
Sune Engsig
Poor data quality puts customer experience at risk. To mitigate that risk, IT-driven enterprises need continuous data cleansing.
From customer relations to resource planning, the right decisions require reliable data. As more and more data sources become available, the risk of data pollution increases.
Major system migrations and even day-to-day operations can affect the reliability of data. So how can you ensure clean data on a regular basis with limited resources?
Why cleanse data?
Whether you are a process owner or system tester, you must be able to trust the data used in your daily work.
Insufficient control over data quality can damage business operations, and even customer experience, if, for example, a warehouse ships the wrong item due to an error in product data.
Faulty data can also cause system downtime, making services unavailable for end-users. Resources are then required to do damage control and to restore availability.
Business data is being polluted in various ways. It often happens during major data migrations between systems.
But even simple, everyday activities can worsen data quality. For example:
- Incorrect use of systems, e.g. error-prone manual data entry
- Use of external data sources without proper data maintenance
- New business processes or rules making current system configurations outdated
In short, daily operations in themselves create a continuous need for data cleansing.
Why most approaches to automated data cleansing fail
Most organizations have this nagging awareness that their ERP or CRM data are inconsistent or messy.
Yet, trying to fix the problem often ends in a deadloc; the people who know about the scope and impact of data issues are not the people who can build the functionality to fix those issues, and vice versa.
The common approach to performing data cleansing is to write scripts for the task. These scripts are then run whenever needed to perform an automated, ad hoc data cleansing.
This script-based approach is problematic for several reasons:
- Script-based automation is resource-intensive: It requires programming skills to create, maintain, and execute scripts. This makes data cleansing dependent on developers – a scarce and costly resource. If data cleansing is in a contest for resources against new product features, the latter will always win.
- Script-based automation is not scalable: A script is usually scenario-specific and might not be reusable across needs in the organization. What’s more, as scripts require maintenance, they will create more workload for developers.
- Script-based automation blurs process ownership: Automating a task, e.g. data cleansing, should not influence the ownership of that process. If someone else than the process owner is automating that process, then ownership might fall between two chairs.
The solution: data cleansing with codeless UI automation
The good news: You already have the people required to automate data cleansing.
If you have a process, you also have an owner. These are subject-matter experts on business processes, as well as the data and applications involved. As such, they are also capable of performing the tasks related to data cleansing:
- Mapping points A and B of the cleansing effort itself
- Identifying business decisions required to support the delivery of data cleansing
- Defining the actions to take in the business application to commit data changes
With all that insight in place, it would make sense if the process owners could automate the data cleansing themselves. Codeless UI automation enables that. It eliminates the disconnect between process expertise and automation expertise.
You’ve probably already been using the graphical user interface (GUI) of your applications for data cleansing. Because that’s how every non-developer specialist interacts with software.
When automation resources are unavailable, specialists across functions need to spend time on tasks like data processing. This is often done manually. For example, by entering data from a spreadsheet into a back- or front-office application.
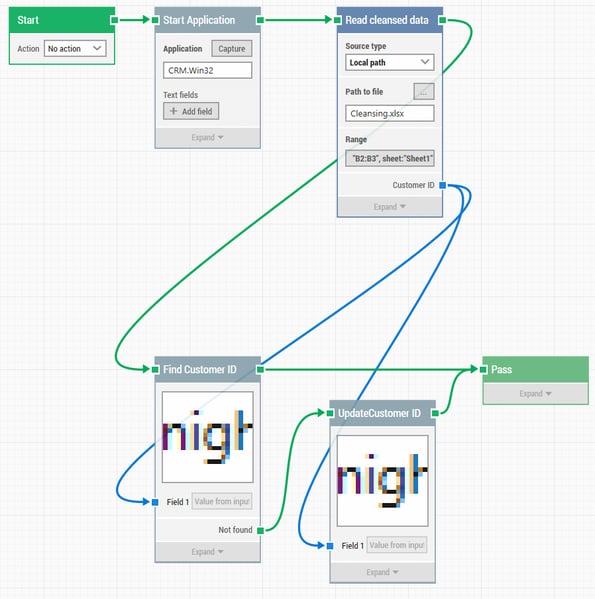
An example of an automated data-cleansing flow built with codeless UI automation in Leapwork.
Notice how one, consolidated data source both drives which data values to find in the application UI and provides the correct data if an entry needs updating.
Obviously, manual, repetitive work prone to error is not the ideal use of a workforce. Instead, business users should be able to design software robots on their own to perform repetitive tasks. For example, data processing, migration, and cleansing.
With UI automation, business users can build automation flows through the same GUI where daily operations take place. This enables users to enforce current business rules when building automated processes. When automating data cleansing this way, you don’t need to recreate the underlying business logic as you would when writing scripts.
Data cleansing leads to data consistency. Data consistency allows your business to make reliable, data-driven decisions.
Download: Automation Tools Comparison
Whether you are already automating test cases, or you are new to the field, it is important to select the right tool. We have made a comparison of the most common tools within the field of test automation:
