
Maria Homann
Are you a programmer looking to automate web applications? If you love writing test scripts, Selenium is probably a good test automation tool for you.
Skip ahead to:
Selenium: A test automation paradox
The codeless Selenium solution
If you don’t love writing code, but you’re tired of manual testing, and you’d like to be able to automate web applications with everything that Selenium testing offers, you’ve come to the right place.
The thing is, Selenium test automation requires users to code. And this presents a challenge for testers - as eight out of 10 manual testers can’t code.

In this blog post, we’re going to cover the pros and cons, and the alternative to Selenium that requires no coding experience at all.
The pros and cons of Selenium
Selenium is free, open-source and supports multiple browsers, operating systems and programming languages.
The challenges of Selenium? It requires coding skills, it takes time to set up and maintain, it requires third party integrations to carry out many testing processes, and with Selenium, you can’t carry out end-to-end testing.
If you’re reading this blog post, you probably did a search for codeless automation because you, like almost every other tester out there, aren’t all that excited about coding. You might have some coding skills, but it’s not exactly your forté.
Well, you’re not alone.
Selenium: A test automation paradox
In many ways, test automation is a bit of a paradox: It’s supposed to relieve testers from manually executing test cases, and with that, save them time and keep them from making mistakes.
But in reality, automating has become almost synonymous with programming. This means testers end up spending more time on setting up the automation, and they risk making lots more mistakes in the process, because most of them don’t know how to automate with script in the first place.
Even if the team manages to set up the automation (perhaps the task of writing the automation script is given to a developer instead), it still takes an enormous effort to maintain the beast that an automated test suite in Selenium typically becomes.
Below are two images of test cases – one is set up with Selenium, the other with a codeless automation tool. Which one do you think is the easiest to set up and maintain?
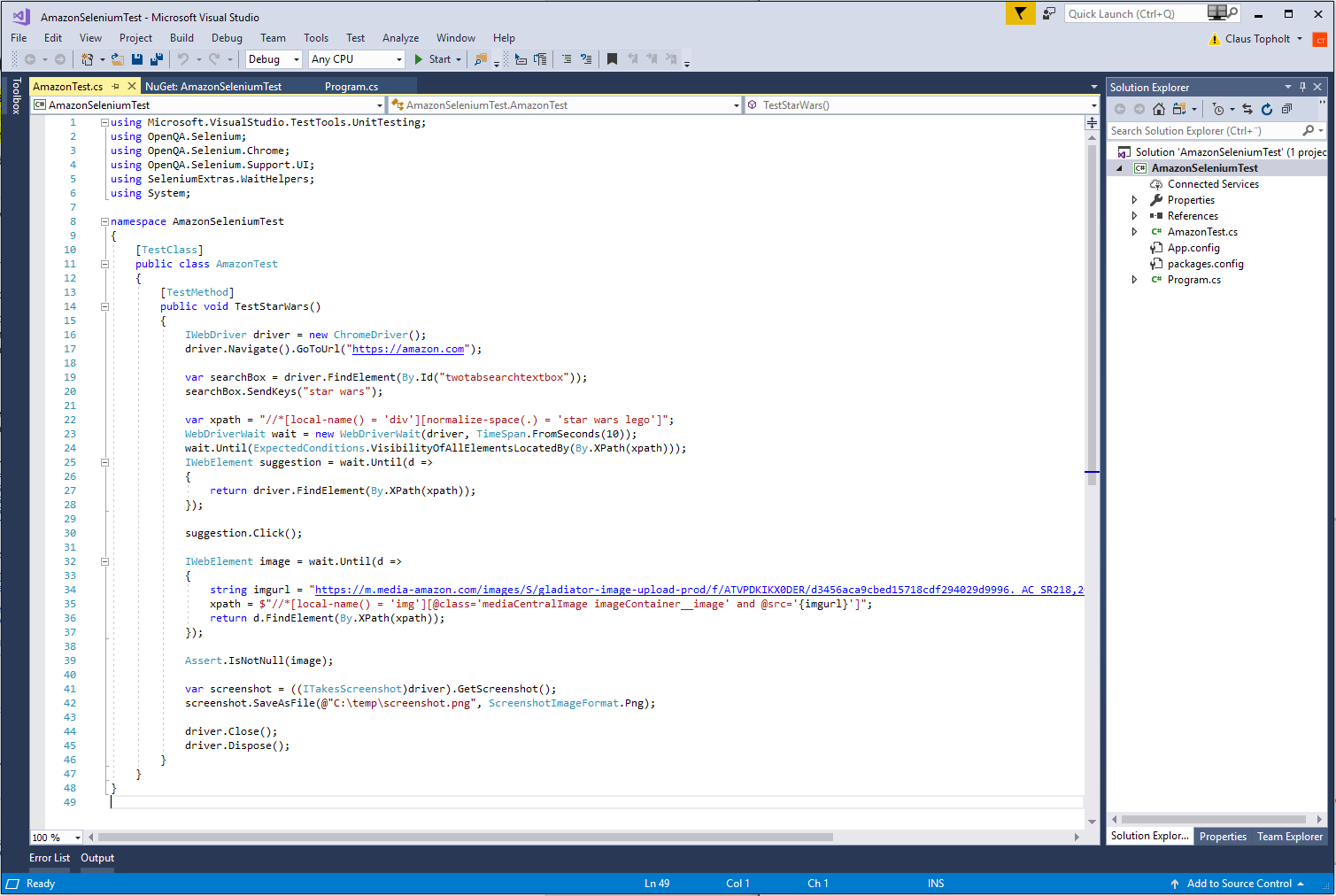
Image: A Selenium script testing the Amazon web shop search functionally.

Image: A Leapwork visual test automation case testing the Amazon web shop search functionality.
The codeless Selenium solution
A codeless version of Selenium, like the one on the second image above, is to many testers a far more ideal user experience.
This is why codeless automation tools have grown in popularity as they relieve many headaches for software testing teams.
A tester who wants to automate testing with Selenium must first learn a programming language such as Python, Java or C#.
On top of that, Selenium isn’t an intuitive tool, and it doesn’t offer 1:1 support. You must either take a course in Selenium, have a go at Selenium’s user documentation, reach out to the community for answers, or take a good old-fashioned learn-by-doing approach.
In contrast, codeless test automation allows every team member, regardless of skill level, to set up and execute test cases from day one.
This can shorten the test suite setup time substantially.
Comparing Selenium and codeless Selenium
Watch the video below to see how fast the user of a no-code test automation platform sets up a test case compared to a Selenium user.
Video: A side by side of Leapwork test automation and Selenium creating the same test case.
For the tester, this means simplifying the testing process of creating testing scenarios by replacing written scripts with visual building blocks. For the developer, this means speeding up the entire process, and letting them focus on software development and innovation.
On top of time and skill limitations lies another problem: maintenance. For testers, this is perhaps the biggest headache of them all.
Particularly in an enterprise environment, test suites can be large and complex, making them difficult and time-consuming to maintain.
With a test automation tool that hides the code behind the scenes and only shows the most necessary actions and steps up front, the tester can much more easily keep an overview of the steps and detect if changes need to be made.

Leapwork: A codeless automation tool
There are many benefits to adopting a test automation tool that doesn’t require any coding. Leapwork is such a tool.
This no-code platform requires zero coding skills (you don’t even have to be able to read code, which is otherwise required in many other automation tools that claim to be code-free), and it’s easy to use because of its visual drag and drop interface.
This makes Leapwork a testing platform that enables fast, error-free test execution. It also enables the CI/CD-focused organization to deliver quality at speed.
To understand the full benefits that Leapwork offers over Selenium, we encourage you to read our comparison of Selenium vs. Leapwork. This comparison gives insight into usability and adoption, documentation and governance, applications support, as well as test execution and integrations.
