
Maria Homann
In the era of rapid digital transformation, where software updates are constant and expected to be seamless, the importance of regression testing cannot be overstated.
However, while regression testing is an important part of testing, it is also one of the most time-consuming and error-prone.
In this guide, we take you through the ABCs of regression testing. From what it is and is not, the power of test automation - when done right - and the impact it can hasve on overall speed and quality, and the tools for regression testing that you can follow to alleviate the regression testing burden and enhance quality. This will help you and your QA team ensure high test coverage with every release, no matter how frequent.
Skip ahead to:
- What is regression testing?
- Why should you do regression testing?
- How frequently should you run your regression tests?
- What is the difference between retesting and regression testing?
- How to prioritize and select regression tests
- Manual vs automated regression testing
- How to do regression testing manually
- How to do automated regression testing: best practices
- The benefits of automated regression testing
- How to choose regression testing tools: the main criteria
- Best regression testing tools: Top 8 list
What is regression testing?
The verb regress (from regression testing) means to return to a former state or condition. Regression testing is a vital component in the testing lifecycle, whether you are checking simple web application functionality or complex, end-to-end business workflows. It safeguards your applications and processes against bugs as they evolve over time. This is because every software update requires testing to ensure that things do not break.<
Simply put, there are two sides of testing:
- Testing new features
- Testing existing functionality
Regression testing focuses on the latter. It is the process of testing existing functionality when new code alterations are made. Every now and then, however, updates can go wrong and cause disruptions to the user experience.
Regression testing ensures that the new modifications work as intended and that previous functionality remains intact and bug-free. These tests are usually performed frequently and consistently, acting as a safety net to quickly identify and rectify regressions before they affect production.
Watch this snippet from our Regression Testing Webinar to hear how our experts explain it in simple terms:
There is always a risk that new code can impact existing code. Many of the most critical functions lie in the things that already exist, and when left untested you are exposing these processes to risk.
Regression testing, however, is not the same as retesting. But the two are often confused. We outline their differences in the next section.
Why should you do regression testing?
At its core, regression testing is not just about identifying bugs introduced by recent changes; it is a strategic approach to maintain and enhance software quality over time.
By systematically retesting the application after each change, developers can quickly detect and fix any issues, thereby preventing potential defects from progressing to later stages of development or into production. This is important because bugs become so much more expensive to fix once they reach production.
How frequently should you run your regression tests?
Your regression suite should ideally be run whenever a change is made to the code. If your software system is large and complex, this is only possible to do with automation.
What is the difference between retesting and regression testing?
Software testing consists of several types of tests. In that mix is regression testing and retesting, of which both can be easily confused. They sound alike, and they have similarities too.
The main difference is that regression testing is designed to test for bugs you do not expect to be there. Retesting is designed to test for bugs you do expect to be there.
What is retesting?
While regression testing means to return to a former state or condition, retesting (also known as confirmation testing) is a targeted testing approach.
Instead of being designed to search through all the previous updates and features of the software to find unforeseen defects and bugs, retesting is designed to test specific defects that you have already detected (typically during your regression testing run).

The process involves re-running the test cases that initially failed, but this time on the corrected code. This step ensures the issues have been resolved. The process concludes with verifying test results, updating defect statuses, and documenting the entire process for quality assurance risk management and record-keeping.
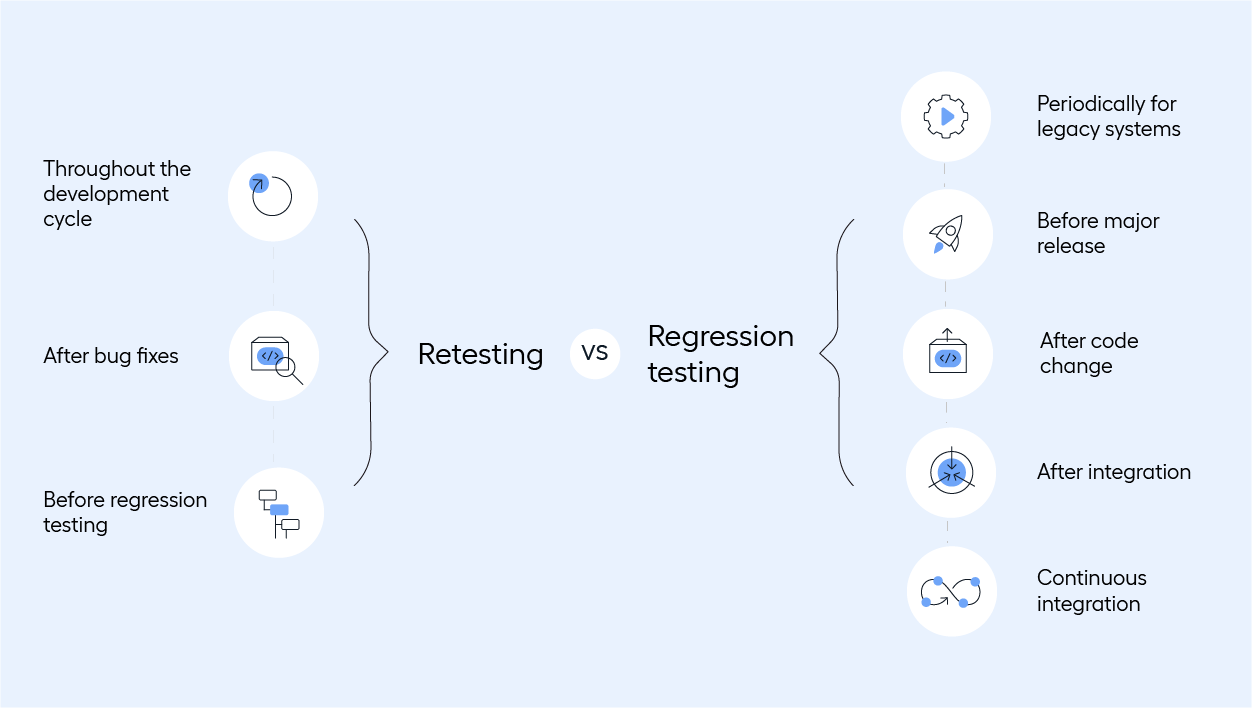
When is retesting and regression testing done?
Besides the differences in their purpose and scope, these tests are carried out at different points.
Regression testing is conducted at various stages of the development cycle, particularly:
- After any code change: Whenever modifications are made to the codebase, whether it is adding new features, fixing bugs, or optimizing existing code, regression testing is performed. This ensures that the new changes do not adversely affect the existing functionalities.
- Before major releases: Prior to a major product release, comprehensive regression testing is recommended. This helps in identifying any last-minute issues that could impact the user experience or software performance.
- After integration of components: In projects where different modules or components are developed separately and then integrated, regression testing is critical. It ensures that the integrated components work seamlessly together.
- In Continuous Integration environments: In CI/CD pipelines, regression testing can be automated and run as part of the continuous integration process. This allows teams to identify and address integration issues as soon as they arise.
- Periodically for legacy systems: For applications that are in maintenance mode or not actively developed, periodic regression testing is advisable, especially when these systems interact with other software that is frequently updated. This proactive approach helps in ensuring that legacy systems remain compatible and functional over time.
Note: There are further nuances here depending on whether you are carrying our manual or automated regression tests. You can skip ahead to our section on manual vs. automated testing to learn more.
Retesting is performed after a defect has been identified and a corresponding fix has been implemented. The main timeline for retesting is as follows:
- After bug fixes: Once developers have addressed the bugs identified during initial testing phases, retesting is carried out. It is a verification process to ensure that the specific issues have been resolved.
- Before regression testing: Retesting is usually done before regression testing. The reason is to confirm that the defect fixes are successful and have not introduced new bugs that could affect the upcoming regression testing phase.
- Throughout the development cycle: Retesting can occur multiple times throughout the development cycle, especially in agile environments where changes and fixes are frequent. Each time a bug is fixed, retesting is necessary to ensure the fix is effective.
Retesting and regression testing in action: case example
The case below shows an example of what regressing testing and retesting look like in practice. Take, for example, a retail e-commerce platform. The stages involving regression and retesting could go as follows:
A tester discovers an issue where customers are unable to add items to their shopping cart via the ‘Quick Add' functionality shown in the image below.
After identifying and documenting this critical bug, the issue is handed over to the development team to fix.
Once a developer addresses the problem and updates the system, the tester retests the shopping cart functionality to ensure that items can now be successfully added to the cart. They also run an automated set of regression tests to ensure that the fix has not inadvertently affected other website features.
This focused retesting confirms that the specific problem is resolved, and the e-commerce site operates as intended for customers.
To help illustrate their differences in a more concrete and usable way, we have illustrated their key differences below.
|
|
Regression testing |
Retesting |
|
Purpose |
To ensure that new code changes have not disrupted any existing functionalities. |
To confirm that specific issues have been resolved. |
|
Scope |
Involves testing a general area of the software. |
Involves testing a specific feature of the software. |
|
Focus |
Is a broad and comprehensive approach to identifying any new bugs introduced by recent changes. |
A narrow approach focused on verifying the fixes of specific bugs. |
|
Test case selection |
A broader set of test cases is chosen, often including those unrelated to recent changes, to ensure overall software health. |
The test cases are selected based on the bugs previously found. |
|
Fit for automation |
Is ideal for automation as the testing suite will grow with time as the software evolves. |
Is not ideal for automation as the case for testing changes each time. |
|
Role |
Should always be a part of the testing process and performed each time code is changed and a software update is about to be released. |
Is sometimes a part of the testing process, specifically if a defect or bug is found in the code. |
|
Timing |
Is often conducted repeatedly, especially after major code changes, before a release, or after integration of new features. |
Is conducted after defects are fixed but before the software moves forward in the development cycle. |
Now that the basics of what is and is not considered a regression test has been clarified, how should you go about prioritizing the tests to include in your regression suite? We cover this in the next section.
How to prioritize and select regression tests
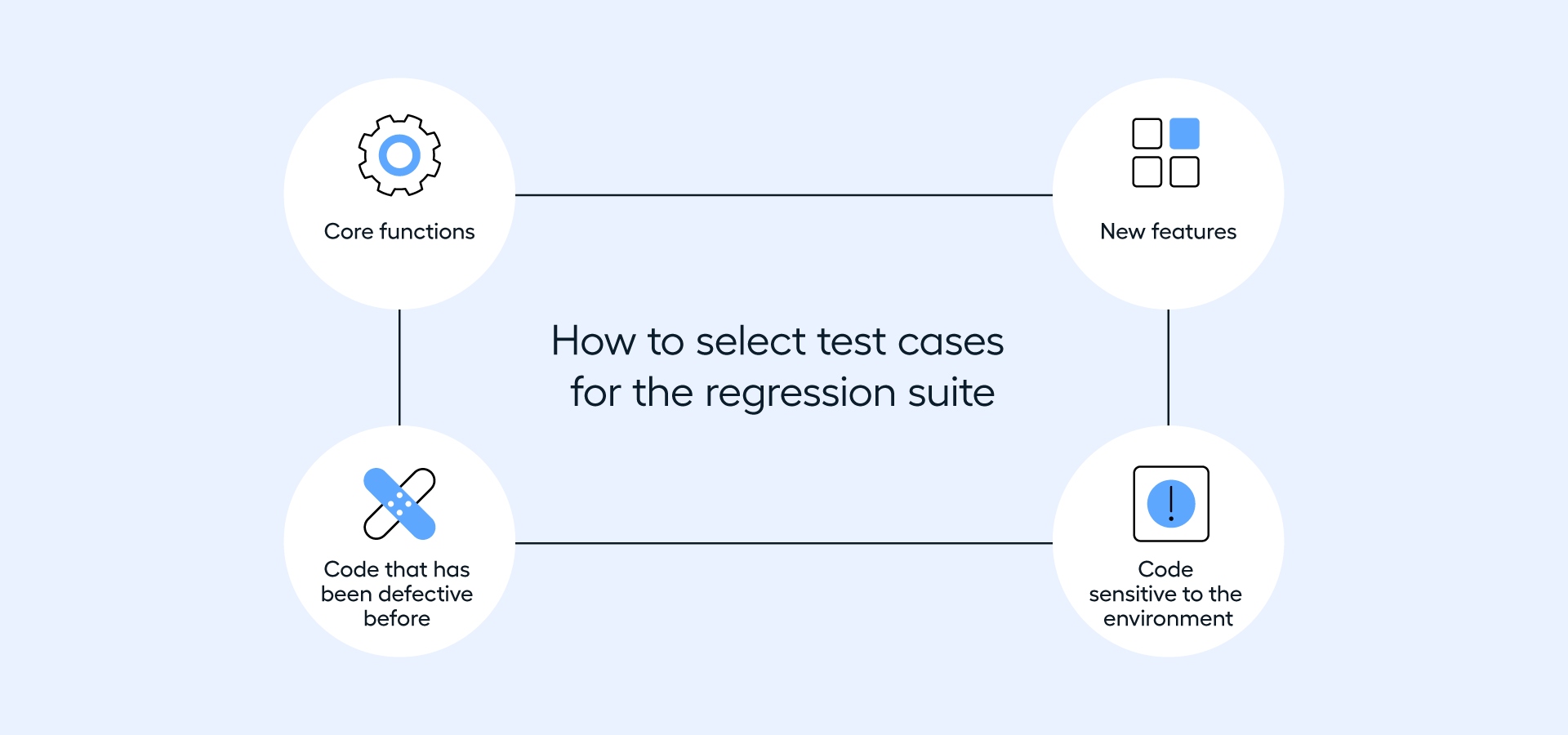
The next step involves selecting the tests for your regression suite. You can't test everything, so determining how to prioritize the test cases is important. Use the following prompts as guidance for building your regression testing suite:
- Is the function core to your product? Is it essential for other functionalities to work? Core functions should always be tested.
- Is the feature new, and has it been tested against numerous other feature updates before? New code tends to be more vulnerable.
- Is the code sensitive to the environment being configured? Dependency on environment settings tends to be more vulnerable.
- Has the code been defective before? It's worth paying extra attention to code that has previously been faulty.
Teams with limited resources or time (especially ones relying on manual testing) may have to take a risk-based approach, where the tests with the highest risk of breaking come first.
If you need additional help organizing which tests to prioritize, there is a framework below which provides examples.
| Priority | Definition | Example |
| 1: Sanity test cases | These are test cases that verify the basic functionality of the product and pre-system acceptance tests. They are critical for ensuring that the application's core features are functioning correctly before proceeding to more detailed testing. | For a web-based email application, Priority 1 test cases would include verifying that users can log in, compose, send emails, and log out successfully. Additionally, ensuring that the homepage loads correctly, and essential navigation elements are functional is crucial at this stage. |
| 2: Crucial non-core features | This category encompasses test cases for features that are important to the application's overall performance but not fundamental to its operation. These features significantly contribute to the user experience, and although the application could technically function without them, their absence would result in a suboptimal performance. | In the email application, Priority 2 would cover features like the ability to attach files to emails, utilize search functionality to find old emails, and apply filtering options to organize the inbox. These features enhance the application's usability and are key to a satisfactory user experience. |
| 3: Lower impact features | These are test cases for features that, while not providing high project value directly to the end user, are important for maintaining code quality and preventing technical debt. These features might not have an immediate impact on the user experience but are crucial for the application's development and maintenance. | Features such as the ability to customize the appearance of the inbox, integration with external calendars, or setting up automated out-of-office replies fall under Priority 3 for the email application. Although these features do not affect the core functionality of sending and receiving emails, they enhance the overall utility and user satisfaction, contributing to long-term engagement. |
As a regression suite grows, many teams shift from a purely manual testing approach by introducing automated testing. In the next section you will find an extensive section on the tests that are best suited for manual or automated regression testing. Also included are the steps involved in adopting a manual vs automated approach.
Manual vs automated regression testing
While automation is handy, it cannot mimic the judgement sometimes required when evaluating software from the perspective of a human.
Whether you are automating regression testing or manually regression testing, the types of tests you would typically carry out differ. The table below can serve as a helpful point of reference when defining the regression test cases for automation and those that should be kept manual.
| The tests best suited for manual regression testing | The tests best suited for automated regression testing |
| Exploratory testing: This involves testing the application without predefined cases or scripts, allowing testers to explore the software's capabilities and uncover issues based on their understanding and intuition. Exploratory testing is a manual process and leverages the tester's creativity and experience. | Highly repetitive tests: Test cases that need to be executed repeatedly over different versions of the software are ideal candidates for automation. Automating these tests saves significant time and effort in the long run. |
| Tests requiring human judgement: Some aspects of the application, such as user experience (UX), visual appeal, and usability, require human judgement to assess. Manual testing is crucial for evaluating the software from an end-user's perspective. | Data-driven tests: Automated regression testing is particularly effective for data-driven tests, where the same set of actions need to be validated against multiple sets of data inputs. Automation can efficiently handle variations in data inputs and outputs. |
| Newly developed features: When features are new and potentially unstable or subject to change, manual testing can be more practical. It allows testers to become familiar with the features and identify any major issues before creating automated tests. | Load and performance tests: Automated tests are essential for assessing how changes in the software affect its performance and behavior under load. Manual testing cannot accurately simulate thousands of simultaneous users or assess response times effectively. |
| Complex user interactions: Tests that involve complex user interactions, especially those requiring precise timing or nuanced input, may be more effectively performed manually. Automation scripts can find it challenging to replicate some sophisticated human behaviors accurately. | Stable areas of the application: Parts of the application that are stable and undergo infrequent changes are good candidates for automation. Once automated, these tests can be run regularly without the need for frequent updates to the test scripts. |
| Smoke and sanity tests: Automated smoke tests can quickly verify that the key functionalities are working as expected after a new build is deployed, making them an efficient first line of defense in regression testing. |
While the table above outlines the tests best suited for manual and automated regression testing, the process for both approaches are different. The steps involved in manual and automated testing are covered in detail in the next section.
How to do regression testing manually
Simply put, manual testing is the process of letting people, often business experts from other departments who are closest to the business processes, run through regression tests.
This process is very tedious, time intensive and is prone to error. However, it still serves an important purpose in ensuring the quality of your application. Here's the steps involved:
Step 1: Understand the changes and impact analysis
Begin by understanding what changes have been made to the application. This could be new features, bug fixes, or updates. Then, conduct an impact analysis to identify the areas of the application that could be affected by these changes. This helps in prioritizing the test cases that need to be executed.
Step 2: Select relevant test cases
Start with your existing test suite. Select test cases that are relevant to the changes made as well as those that cover critical functionalities of the application. Then, modify existing test cases, if needed, to cover the new changes. Add new test cases to cover any new features or scenarios introduced.
Step 3: Prioritize test cases
Hard prioritization is critical when testing manually - you will not have time to cover everything. Prioritize test cases based on the criticality of features, the impact of changes, and the risk of defects.
Focus first on functionalities that are directly affected by the changes. Then, decide on the depth of regression testing based on the release cycle and the extent of changes. For minor changes, a shallow regression might suffice, whereas major releases might require a deep regression testing effort.
For more on prioritizing regression tests, go back to our section on prioritization.
Step 4: Execute test cases
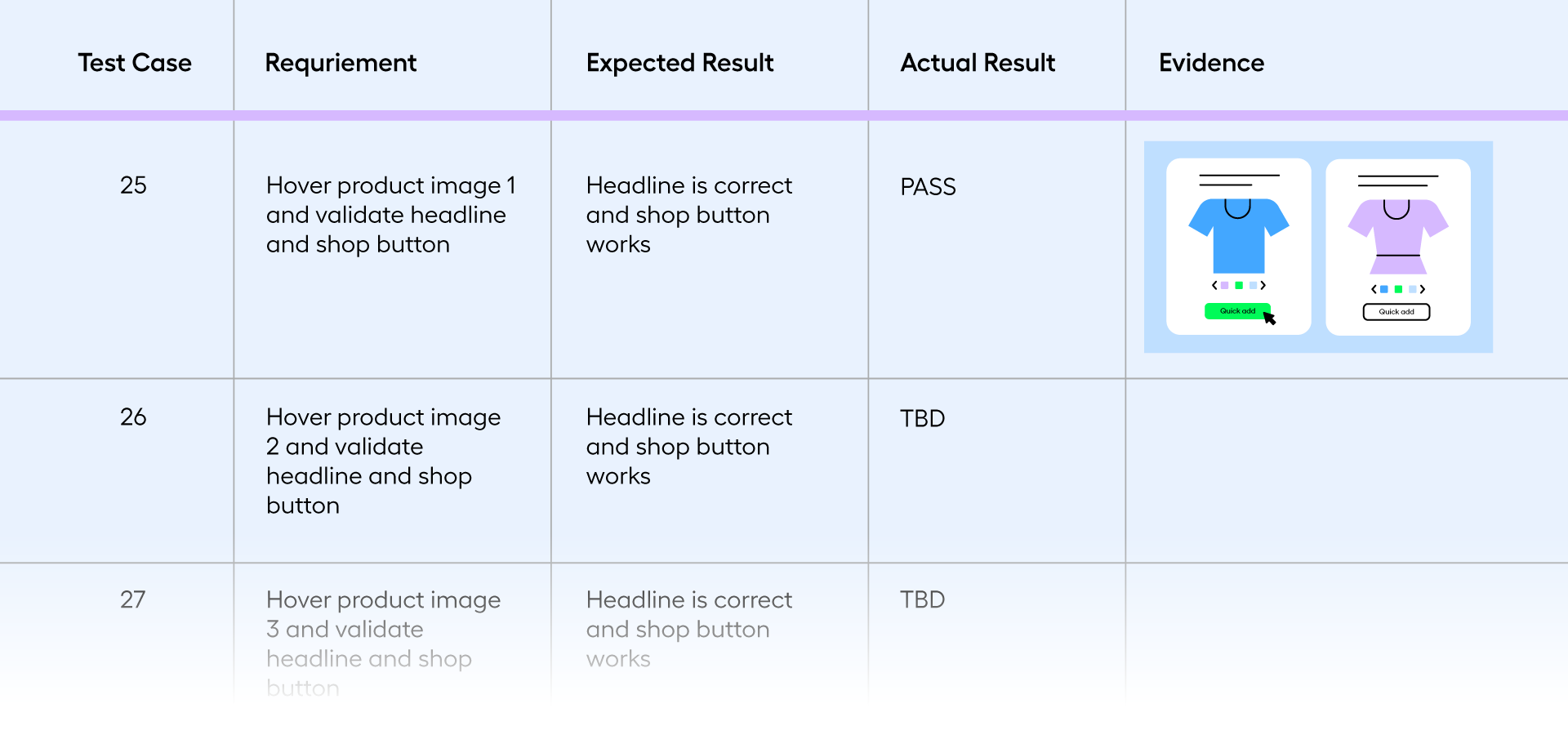
Execute the selected test cases methodically. Follow the test steps carefully and observe the application behavior. Document any deviations from expected results. Capture screenshots, logs, or any other relevant information that can help in debugging.
Below is an example of a series of manual test cases that are designed to validate a web shop's functionality. The requirements and expected results are described on the left side of the spreadsheet, and the results are documented on the right with a simple pass/fail grading system as well as a screenshot.
Step 5: Log defects
Log defects for any discrepancies found during testing. Provide detailed information to help developers understand and fix the issues. Once defects are fixed, verify the corrections in the next regression cycle to ensure that the fixes haven't introduced new issues.
Step 6: Continuous improvement
Use insights and data from regression testing to improve the testing process. Identify frequently failing areas and adjust your testing strategy accordingly. Regularly update your test suite to reflect changes in the application and to remove obsolete test cases.
Step 7: Communication and collaboration
Work closely with developers, business analysts, and other stakeholders. Effective communication ensures that everyone understands the scope of regression testing and the findings. Share regression testing results with the team, highlighting any critical issues found and the overall quality of the release.
Many testers consider manual regression testing particularly tedious; it is a bit like being given the task of searching through a haystack for a needle that probably is not there. And you do not just have to do it once, you must do it every time new code is created.
What is more, the suite of regression tests grows with the product, meaning that over time, it becomes practically impossible to execute and maintain manually.
While automation will never fully replace aspects of manual testing, many QA teams choose to automate their regression testing for agility if the tests meet the requirements of a good automation case.
How to do automated regression testing: best practices
There is not necessarily one right approach to automated regression testing, but you can save your team a lot of time and resources by thinking the process through from the start. This will not only help increase output quality but will also help contain costs.
We have put together these 11 steps to guide you through the planning process, and to hopefully save you some time down the road.
Find additional expert information on automating regression testing in our on-demand webinar on how to make your testing more efficient.
Step 1: Risk analysis
Risk analysis should not just be a part of your regression testing automation strategy, but your test automation strategy as a whole.
It can be difficult and time-consuming to try to foresee everything that can go wrong, estimate the cost, and find a way to mitigate or avoid that risk. Nonetheless, it is important to at least consider.
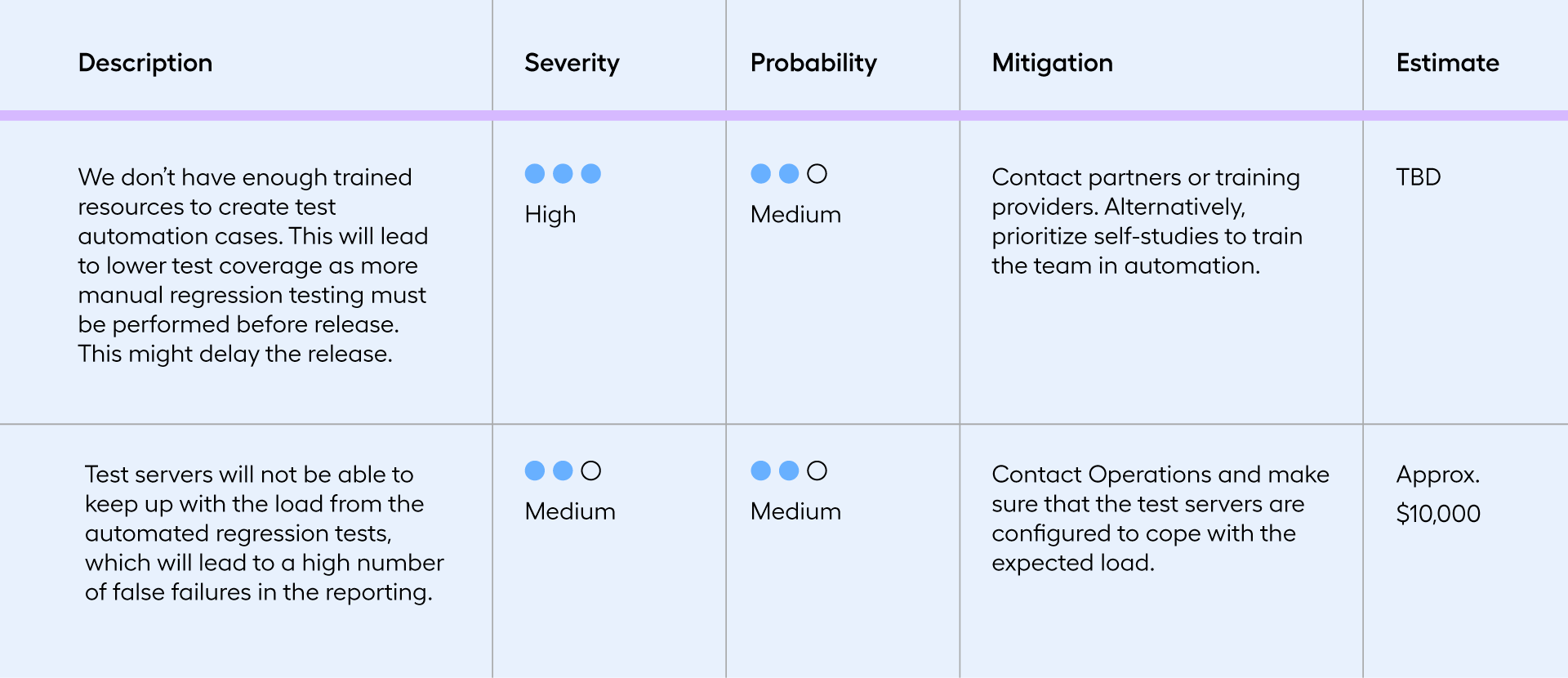
The size of your business and the complexity and importance of your business processes will obviously impact the risk factor of tests. However, you can formalize the extent of the risk by answering specific questions, those being:
- Severity: What will happen if the risk becomes reality? How hard will it hit the project?
- Probability: What is the likelihood that it happens?
- Mitigation: What can be done to minimize the risk?
- Cost estimate: What is the cost of mitigating the risk –what is the cost of not doing it?
If the risks are manifold, and your business does not have the processes in place to mitigate them manually, you may have a case for test automation.
Step 2: Set goals and measure success
Your motivation for reading this article is probably to improve your regression testing initiatives. But how will you prove progress if you do not have a starting point and an end goal? Make sure to set up key performance indicators through metrics such as:
- The test coverage you are aiming to achieve.
- Bugs entering production.
- Speed of testing.
- Speed of releases.
With a clear destination, there is a greater chance you will stay focused on initiatives that will truly move the needle.
Step 3: Select the right tools
The process for automated regression testing starts with the tool, with the assumption that the QA team has a regression testing strategy in place. Don't have a test automation strategy? Here is a guide to help you build one.
Read our guide on best test automations tools for 2026
Once this has been established, you need to identify which applications to automate and the technologies they are based on. This will determine which test automation tool you should be using.
Find more detailed content on regression testing across different technologies:
Salesforce Regression Testing: 8 Best Practices
Regression Testing in Dynamics: What, Why & How
SAP Regression Testing: What, Why, and How
In most cases, regression testing will involve several application types: web-based, desktop-based, mobile apps, and so on. Therefore, it is important to have a tool that can handle all your automation requirements for end-to-end testing.
Many start out automating with the open-sourced code-based tool, Selenium. Selenium is a powerful automation tool for the web and can bring great value if you require automation for a small number of tests. However, if your testing suite goes beyond web, or is large ins scope, you may benefit from using a tool that can scale.
In addition, with code-based tools, developers and testers often end up spending a substantial amount of time on writing automation scripts as well as maintaining all those scripts down the line.
Below is a comparison of two automated regression test processes. One is code-based (Selenium), and the other is no-code and completely visual in setup (Leapwork).

Step 4: Consider the roles and responsibilities
Next, you need to define the roles for automation in your team. Regression testing may not be the only thing you are automating, in which case keeping an overview of who does what is essential. Some examples of the roles and responsibilities include:
- Automation lead: Responsible for coordinating and managing all activities regarding automation in the project.
- Test case designer/reviewer: Like code reviews among software developers, it is important to establish a review process for automated test cases. This means that a tester will typically have at least two roles: test case designer and test case reviewer.
Step 5: Maintain test data and environment
To be able to run automated tests, you need to prepare test data. The tests should be run in a stable and controlled environment. This requires a test environment (this also avoids the corruptions of production data). This test environment should closely mirror the production environment.
Step 6: Design and develop test cases
Similar to manual testing, identify scenarios that need to be tested based on the changes made to the application and its critical functionalities. Depending on your test automation approach, you will need to either develop test scripts by writing code or build them using no-code test automation. Regardless of the approach, make sure the tests are modular, reusable, and easy to maintain.
Step 7: Execute test scripts
Before any automated test cases are added to the regression suite, it is best practice to run and verify the tests multiple times to ensure that they run as expected. False failures are time-consuming, so it is essential that test cases are robust and reliable.
Execution of test cases should be handled either by the pipeline orchestrator (Jenkins, TFS, Bamboo, TeamCity, etc.) or by a scheduling tool. This means that regression tests will run either as part of a build/deployment event or on a known time during the day.
Consider a setup that allows for parallel execution of the test cases to get the feedback from the regression tests back to the development team faster.
Remember, you can never test too much, and the combination of test automation, reliable test cases, and scheduled/controlled execution will inevitably have a positive effect.
Step 8: Analyze test results
Keeping track of test progress and results is as important as creating the tests in the first place. Automated tools typically generate reports that detail the outcome of each test case.
Analyze these results to identify any failures or issues. For any test that fails, log bugs with detailed information for developers to fix. Traceability is important here – you need proof of the test case and where in the test a bug appears.
Having a plan for how to analyze failing test cases and the actions required to take afterwards is a critical—yet sometimes neglected—part of test automation strategy.
The time it takes from the point where a tester is notified of a failing test case until the fix is described, understood, and accepted in the development backlog is usually much longer than teams anticipate. Consequently, release cycles risk being delayed, and the agile team becomes less agile.
Having a well-defined process for this can save a lot of time and frustration throughout the release cycle. A good place to start is to outline how different errors should be handled and by whom. For example:
- Environment issues → Raise a ticket with the DevOps team
- A bug in the application under test → Flag a bug for Development
- A bug in the automation scripts → Create a task for the test team
Step 9: Integrate with CI/CD pipeline
Fast feedback on tests can help speed up the entire development process. This can be achieved by incorporating continuous, automated regression testing early in your CI/CD pipeline. This makes it possible for developers to receive immediate feedback on new code once committed, ensuring faulty code does not pass further into the pipeline. As mentioned before, tools like Jenkins, CircleCI, or GitHub Actions can facilitate this integration.
After a complete run of regression tests, you should consider including the application logs as part of the release decision. If the regression tests have good application coverage, then any errors not related to the UI should reveal themselves in the log files (if your automation tool has such a capability).
For further reading on continuous testing, make sure to get our guide:
Step 10: Maintain and update tests
Every IT landscape in an organization will evolve over time. Either through changes you make, because you are developing the software or creating customizations, or because it is a packaged application and those developing it are pushing out service releases or updates. So, maintenance is a must. You can minimize the maintenance of automated tests by considering two main strategies:
- Stability: Use reliable methods and stable identifiers from the start. Choose automation tools wisely, ensuring they handle expected changes well for the technologies you are using. Proper test data and stable environments are also essential to avoid failures unrelated to application issues.
- Ease of updating: Embrace modularity and reusability in your test designs. Instead of updating tests individually with every development change, ensure that the testing tool you are using allows you to create centrally updatable test components (i.e. instead of building the test component for a login, create the automation once and reuse it every time it is required). This allows for quick adjustments when business processes evolve.
Effective test case design is key, emphasizing a "less is more" approach to ensure clarity and ease of maintenance. These two considerations will help you in quickly updating tests as the application changes, reducing both short-term and long-term workload.
Step 11: Continuous improvement
Use insights from automated testing to refine and enhance your test automation strategy. Identify areas for increased coverage or where manual testing may still be necessary. Continuously optimize the test suite for performance, removing outdated tests and adding new ones as needed.
From here, try to work on enforcing a culture for continuous learning and improvement, where you include and embrace feedback from stakeholders, peers, and all team members working with automation and adjust the strategy where needed.
To streamline your test automation even more, you can create common standards. Work with your testing team to identify universal test components and agree on documentation and naming conventions. This approach prevents the redundancy of components within your regression test suite, maximizing re-usability.
Maintain a document outlining these standards and update it as your team discovers more efficient testing methods. This living document would serve as a guideline for current and future testing practices.
Getting informed about the best practices will help ensure that you save time on regression testing from the start, and do not end up building huge, unmanageable regression suites that take up more time than they give back.
The benefits of automated regression testing
When properly executed, an effective regression testing approach that follows best practices can help teams achieve a lot.
Related reading: Test automation benefits for the CIO, QA lead, and tester
- Automated regression tests can run 24/7, 7 days a week. People do not have to wait for test results during working hours, and testers can focus on more value-generating tasks while regression tests run in the background.
- Automated regression testing frees up resources. These tests pick up the slack of predictable, rule-based, and repetitive testing with high accuracy.
- You can release software updates and customizations to market faster by accelerating the testing process.
- The business can elevate overall software quality by minimizing bugs and issues in the production environment, and user satisfaction will increase due to less bugs reaching the production environment. This means less time spent implementing hotfixes once software is live.
- There will be more confidence overall in the software being released, putting the business is a better position compared to competitors.

Learning about benefits involved in automating your regression testing is one step of the process. Committing to a tool and ensuring that the business is best set up to succeed with this tool is another.
How to choose regression testing tools: the main criteria
Choosing the right regression testing tool involves considering several critical criteria.
Ramping up
- Ease of use: How user-friendly the tool is, particularly for testers who are typically non-technical users.
- Ramp-up time: The ease and speed a team can adopt and start using a tool.
Scaling up
- Collaboration: Whether the tool supports multiple users collaborating.
- Support: The level of customer support provided for global teams.
- Maintenance: How demanding the tool is in terms of upkeep and updates.
End-to-end capabilities
- Applications supported: The tool's ability to support testing across different applications and technologies, indicating its versatility and comprehensiveness.
User reviews
- We included G2's database of user reviews and ratings in our research process to make sure we also had real-world feedback on the best regression testing tools.
Best regression testing tools: Top 8 list
1. Leapwork
Leapwork is a visual test automation platform powered by AI, making it accessible for users without coding skills. Leapwork scores highly on user-friendliness and support, which makes ramp-up and day-to-day management easy. It also supports end-to-end testing across various applications, including web and desktop.
- Ramping up: Easy (intuitive visual platform, templates, and professional services)
- Scaling up: Easy (flexible and scalable architecture with minimal maintenance, made for enterprise teams)
- Application support: Extensive (covers web, mobile, desktop, and virtual environments)
2. Katalon
Katalon provides an automation solution for web, mobile, and desktop testing. Users can use the tool to carry out basic automation through its no code interface, but it requires scripting for more complex scenarios, making it harder to use for non-technical users.
- Ramping up: Easy to moderate (intuitive for developers)
- Scaling up: Moderate (supports codeless automation but requires scripting for complex scenarios)
- Application support: Extensive (covers web, mobile, and desktop applications)
3. Tricentis Testim
Tricentis Testim leverages AI to enhance the speed and stability of tests. It is designed to simplify the creation and maintenance of automated tests through an intuitive technical interface. Tricentis offers comprehensive training services, but does not offer live support.
- Ramping up: Easy to moderate (has smart features for fast test creation, but is technical)
- Scaling up: Easy to moderate (AI assists in maintaining tests, made for enterprise teams, but complex scenarios require deeper customization)
- Application support: Broad (covers web applications and mobile testing)
4. Selenium WebDriver
Selenium WebDriver is a robust tool primarily designed for web application testing. Selenium is an open-source tool that caters to users comfortable with programming. It is highly versatile but requires technical proficiency that may not suit all users. Its open-source nature ensures a vast community support network, although it lacks direct customer service.
- Ramping up: Variable (depends on developer resources and their familiarity with tool and web technologies)
- Scaling up: Difficult (requires code modifications and only community support available, does not have built-in collaboration features)
- Application support: Limited (web applications only)
5. Rainforest QA
Rainforest QA utilizes AI and crowd-sourced human testers to provide rapid, on-demand regression testing services. This platform is ideal for growing teams needing quick feedback on their apps' functionality across various devices and operating systems, but may not be suitable to enterprise use cases.
- Ramping up: Easy to moderate (intuitive platform with minimal setup required)
- Scaling up: Easy to moderate (uses crowd-sourced testing so complex tests may need careful management)
- Application support: Moderate (web applications with some support for mobile applications)
6. TestComplete by SmartBear
TestComplete enables automated testing across multiple platforms and environments through powerful scripting capabilities. It offers robust record and replay features, along with a flexible scripting language that accommodates testers of varying skill levels. TestComplete is supported through documentation and community support.
- Ramping up: Moderate (intuitive interface but requires coding)
- Scaling up: Moderate (made for enterprise teams but can only handle complex scenarios with advanced scripting)
- Application support: Extensive (covers web, mobile, desktop, and virtual environments)
7. Ranorex Studio
Ranorex Studio is a well-rounded automated testing tool that facilitates testing for web, desktop, and mobile applications. The tool offers a blend of codeless test creation for beginners and customizable scripting options for advanced users. Ranorex Studio is made for technical teams and can’t be managed without a team of developers.
- Ramping up: Moderate (intuitive design but comes with learning curve for those new to automation)
- Scaling up: Moderate to difficult (provides robust tools for managing complex test suites, but requires skilled technical resources to maintain)
- Application support: Broad (covers web, desktop, and mobile platforms)
8. Watir (Web Application Testing in Ruby)
Watir is an open-source, lightweight tool specifically designed for automating web browser actions. It is favored by test engineers and developers who prefer Ruby for writing their test scripts. It is distinguished by its simplicity and effectiveness in simulating real user actions on web browsers.
- Ramping up: Variable (depends on programming skills and familiarity with Ruby)
- Scaling up: Difficult (while Watir supports complex test scenarios, extensive Ruby knowledge can be required for advanced features, does not have built-in collaboration features)
- Application support: Limited (just web applications)
Keep learning about regression testing
Each tool in this list offers unique strengths, making them suitable for various testing scenarios and requirements.
When choosing a regression testing tool, consider your project's specific needs, including the technical proficiency of your team, the types of applications you are testing, and your long-term maintenance capabilities.
If you are interested in learning more about regression testing, you can dive deeper through our webinar Automate to Innovate: Mastering Regression Testing with Leapwork.