Get Web Text
A Get Web Text building block is used to find text on a web page or nested inside a web element in an already open browser window when working with web automation. Please note that this block only works with browser windows that were previously opened using the Start Web Browser block or their “child” windows.
Fully expanded, the Get Web Text block shows the following properties:
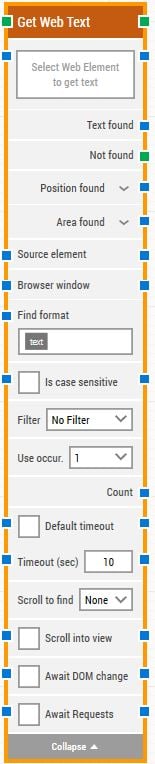
The Block Header (“Get Web Text”)
The green input connector in the header is used to trigger the block to start executing.
The green output connector in the header triggers when the text has been successfully found.
The title of the block (“Get Web Text”) can be changed by double-clicking on it and typing in a new title.
Select Web Element to get text
This property contains the locator for the web element from which the text has to be extracted.
A web element locator can be captured by right-clicking on the property and selecting “Capture new web element”.
Once set, the web element locator can be edited by right-clicking and selecting “Edit web element”. See the many different Learning Center video examples of how this works.
The property can be cleared by right-clicking and selecting “Clear web element”.
Text found
This property contains the text that was found.
Not found
This green output connector triggers if suitable text is not found before the timeout (see below). This is typically used to branch execution flow or to explicitly fail a case by linking it to a Fail block.
Position found
The browser canvas position where the text was found in X, Y coordinates. The top-left corner of the browser canvas is position 0, 0.
Click the Expand button to work with the X and Y coordinates separately.
Please note that any web element that is set to not visible (e.g. using a CSS class) will have position 0, 0.
Area found
The browser canvas position and size of the number found in X, Y, Width, Height coordinates, starting with the upper-leftmost pixel. The top-left corner of the screen is position 0, 0.
Click the Expand button to work with the area’s position and size and their nested sub-properties separately.
Source element
By setting this property, the web element locator will be limited to only work inside the source element.
For instance, if in a previous building block, a table web element found, by setting that as the source element, it’s possible to search for text inside only that table.
Browser window
By setting this property, the building block will use a specific browser window.
Find format
Define a format that the text must meet to be retrieved. For instance, by defining “Status: [TEXT] today” only text inside paragraphs such as “Status: Green Mode today” will be retrieved.
Is case sensitive
Select whether the format should be case sensitive. By default, it is case insensitive.
Filter
Define a filter that the text must meet to be retrieved. For instance, only retrieve numbers that “Starts with” the word Green.
Filter value
The value used by the filter.
Use Occurrence
Select which occurrence of the text to use, if more than one is found.
Select “All” to iterate through all of the occurrences. By selecting “All”, the sub-properties Current index and Completed are shown (see below).
Current index
The current index when iterating through all occurrences of found text.
Completed
This green output connector triggers when the iteration of all occurrences are completed.
Default timeout
If the 'Default Timeout' property checkbox is not selected, then the timeout value is 10 seconds. If the 'Default Timeout' property checkbox is selected, then the 'Default timeout' value selected in the flow settings will be applicable.
Timeout
The maximum time spent searching for the text before giving up and triggering “Not found” (see above).
Note: All cases have a “global timeout” that can be configured in the “Settings” panel. This is unrelated to the timeout of a single building block. However, a running case will automatically be cancelled if it runs for longer than the global timeout.
Scroll to find
When a value other than “None” is selected, the building block will use scrolling when searching for text. This can be useful when searching in scrollable content such as web pages where elements are loaded asynchronously, e.g. using infinity scroll.
Max repeats
The maximum number of times to perform a scroll before giving up searching for text.
Amount
The amount of scrolling that will be performed on each scroll repeat.
Delay (sec)
The delay in seconds between each of the scroll amounts.
Scroll into view
When checked, any found number’s containing web element is automatically scrolled into view.
Await DOM Change
Delay the search for the web element until there has been no changes to the page’s DOM for a specific period of time — for instance 3 seconds.
This is useful when waiting for behind-the-scenes updates in javascript to occur. Regardless of this checkbox, the search and click will occur after waiting a maximum of 30 seconds.
Await Requests
Delay the search for the web element until there has been no active XHR requests for a specific period of time — for instance 3 seconds.